Annuncio pubblicitario
Code 42, la società dietro CrashPlan ha deciso di farlo abbandonare completamente gli utenti domestici CrashPlan Shutters Cloud Backup per utenti domesticiCode42, la società dietro a CrashPlan, ha annunciato che sta abbandonando gli utenti domestici. CrashPlan for Home viene eliminato, con Code42 invece si concentra interamente su aziende e clienti aziendali. Leggi di più . I prezzi super competitivi hanno reso la loro soluzione di backup una tale tentazione per le persone con grandi esigenze di backup. Mentre la loro incapacità di mantenere le promesse può aver seminato semi di sfiducia, ci sono altri fornitori di cloud. Ma di quale provider ti fidi del tuo archivio di meme?
Attualmente il leader mondiale nel cloud computing è Amazon Web Services (AWS). La curva di apprendimento per AWS può sembrare ripida, ma in realtà è semplice. Scopriamo come sfruttare la piattaforma cloud leader nel mondo.
Soluzione di archiviazione semplice
La soluzione di archiviazione semplice, comunemente denominata S3, è il colosso di Amazon di una soluzione di archiviazione. Alcune importanti aziende che usano S3 includono Tumblr, Netflix, SmugMug e, naturalmente, Amazon.com. Se la mascella è ancora attaccata al viso, AWS garantisce una resistenza del 99,999999999999 percento per la sua opzione standard e una dimensione massima del file (di ogni singolo file) di cinque terabyte (5 TB). S3 è un archivio oggetti, il che significa che non è progettato per l'installazione e l'esecuzione di un sistema operativo, ma è perfettamente adattato per i backup.
Livelli e prezzi
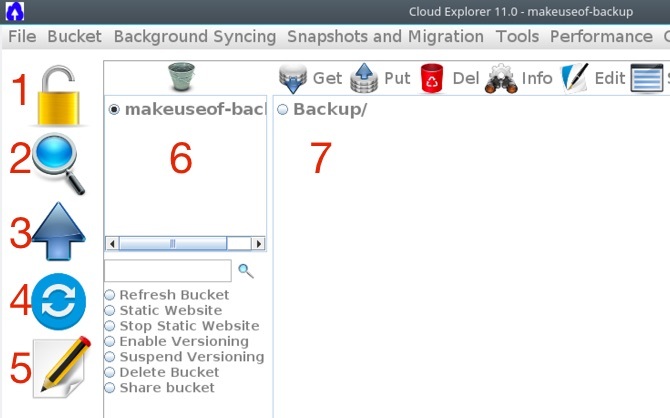
Di gran lunga questa è la parte più complicata di S3. Il prezzo varia da regione a regione e il nostro esempio utilizza i prezzi correnti per la regione degli Stati Uniti (Virginia del Nord). Dai un'occhiata a questo tavolo:

S3 è composto da quattro classi di memoria. Standard ovviamente è l'opzione standard. Accesso raro è complessivamente più economico per archiviare i tuoi dati, ma è più costoso far entrare e uscire i tuoi dati. Ridondanza ridotta viene generalmente utilizzato per i dati che è possibile rigenerare in caso di smarrimento, come ad esempio le miniature delle immagini. Ghiacciaio viene utilizzato per l'archiviazione in quanto è il più economico per l'archiviazione. Tuttavia, saranno necessarie dalle tre alle cinque ore prima di poter recuperare un file da Glacier. Con ghiacciai o celle frigorifere, si riducono i costi per gigabyte ma aumentano i costi di utilizzo. Ciò rende la cella frigorifera più adatta all'archiviazione e al ripristino di emergenza. Le aziende in genere sfruttano una combinazione di tutte le classi per ridurre ulteriormente i costi.
Il meglio in ogni categoria è contrassegnato in blu. durabilità è quanto è improbabile che il tuo file vada perso. A parte la ridondanza ridotta, Amazon dovrà subire una perdita catastrofica in due data center prima che i dati vengano persi. Fondamentalmente, AWS memorizzerà i tuoi dati in più strutture con tutte le classi tranne la classe ridondante ridotta. Disponibilità è improbabile che ci siano tempi di inattività. Il resto è più facile dimostrato per mezzo di un esempio.
Esempio di utilizzo
Il nostro caso d'uso è il seguente.
Voglio memorizzare dieci file su S3 Standard con una dimensione totale di un gigabyte (1 GB). Caricamento dei file o Mettere incorrerà nella richiesta di un costo di $ 0,005 e $ 0,039 per lo spazio di archiviazione totale. Ciò significa che nel primo mese ti verrà addebitato un totale di circa 4,5 centesimi ($ 0,044) e poco meno di 4 centesimi ($ 0,039) per il parcheggio dei dati in seguito.
Perché esiste una struttura dei prezzi così complicata? Questo perché è pay-for-what-you-use. Non paghi mai nulla che non usi. Se si pensa a un'azienda di grandi dimensioni, ciò offre tutti i vantaggi di disporre di una soluzione di archiviazione di livello mondiale, mantenendo i costi al minimo assoluto. Amazon fornisce anche a Calcolatrice mensile semplice quale puoi trovare qui, così puoi proiettare la tua spesa mensile. Fortunatamente, offrono anche un livello gratuito, a cui puoi iscriverti qui, così puoi provare i loro servizi per un massimo di 12 mesi. Come per qualsiasi cosa di nuovo, una volta che inizi a usarlo, diventa più comodo e comprensibile.
La console
Il livello gratuito di AWS ti consente di provare tutti i loro servizi, in una certa misura, per un anno intero. All'interno del livello gratuito, S3 offre 5 GB di spazio di archiviazione, 20.000 get e 2.000 put. Ciò dovrebbe consentire un ampio spazio di respirazione per provare AWS e decidere se soddisfa le tue esigenze. La registrazione ad AWS ti guida in pochi passaggi. Per la verifica avrai bisogno di una carta di credito o di debito valida e di un telefono. Una volta avviata la console di gestione, verrai accolto nella dashboard di AWS.
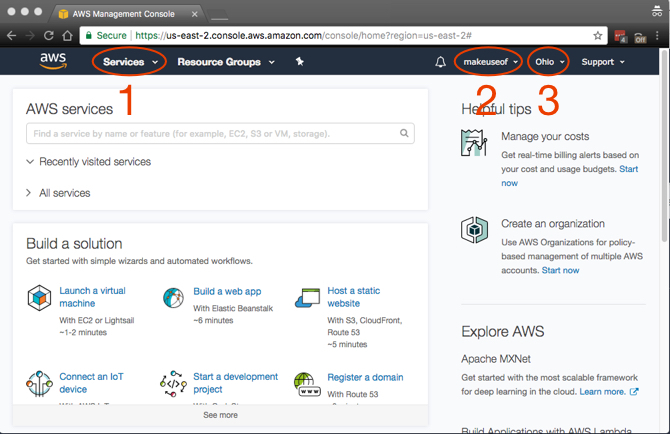
A prima vista, potrebbe sembrare che ci sia un sacco di cose da prendere, e questo è semplicemente perché c'è. Gli elementi principali a cui accederai, che sono annotati nello screenshot, sono:
- Servizi: Sorpresa, sorpresa, qui troverai tutti i servizi AWS.
- Account: Per accedere al tuo profilo e fatturazione.
- Regione: Questa è la regione AWS in cui stai lavorando.
Poiché desideri la latenza più bassa tra i tuoi computer e AWS, scegli una regione più vicina a te. Esistono alcune regioni che non dispongono di tutti i servizi AWS ma vengono implementate su base continuativa. Fortunatamente per noi, S3 è disponibile in tutte le regioni!
Sicurezza S3
Prima di continuare, il primo lavoro è proteggere il tuo account. Clicca su Servizi> Sicurezza, identità e conformità> IAM. Nel frattempo, garantiremo anche le autorizzazioni necessarie al tuo computer, in modo che tu possa eseguire il backup e il ripristino in modo sicuro.
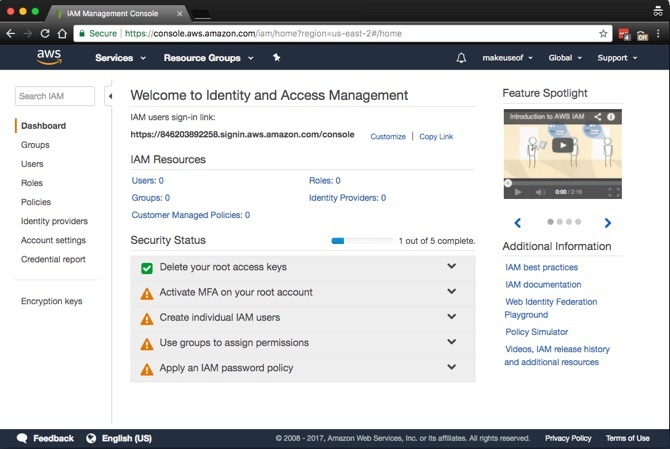
Questo è un semplice processo in cinque fasi. Noterai dallo screenshot che MFA può essere attivato sul tuo account. Sebbene l'autenticazione a più fattori (MFA), nota anche come autenticazione a due fattori (2FA) Come proteggere Linux Ubuntu con l'autenticazione a due fattoriDesideri un ulteriore livello di sicurezza sul tuo login Linux? Grazie a Google Authenticator, è possibile aggiungere l'autenticazione a due fattori sul PC Ubuntu (e su altri sistemi operativi Linux). Leggi di più , non è richiesto, è altamente raccomandato. In poche parole, richiede una combinazione di nome utente e password, insieme a un codice sul dispositivo mobile. Puoi ottenere un dispositivo MFA fisico compatibile o utilizzare un'app come Google Authenticator. Vai a uno dei App Store o il Play Store per scaricare l'app Google Authenticator.
Utilizzo dell'autenticazione a più fattori opzionale
Espandere Attiva MFA sul tuo account di root e clicca su Gestisci AMF. Assicurarsi Un dispositivo MFA virtuale è selezionato e fare clic Passo successivo.
Apri Google Authenticator sul tuo dispositivo ed esegui la scansione del codice a barre visualizzato sullo schermo. Digitare il codice di autorizzazione in Codice di autorizzazione 1 box e attendi che il codice si aggiorni in Google Authenticator. Sono necessari circa 30 secondi per visualizzare il codice successivo. Digita il nuovo codice in Codice di autorizzazione 2 scatola da Google Authenticator. Ora fai clic su Attiva MFA virtuale pulsante. Dopo aver aggiornato lo schermo, Activate MFA avrà il segno di spunta verde.
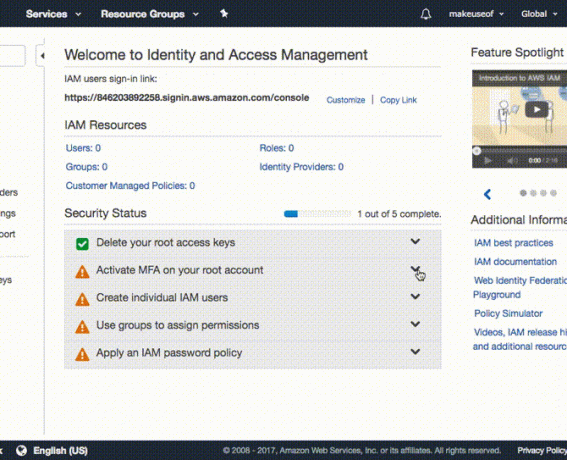
Ora dovresti avere MFA attivato sul tuo account e aver collegato Google Authenticator ad AWS. La prossima volta che accedi alla Console AWS, dovrai digitare normalmente il nome utente e la password. AWS ti chiederà quindi un codice MFA. Questo sarà ottenuto dall'app Google Authenticator proprio come hai fatto nel passaggio precedente.
Gruppi e autorizzazioni
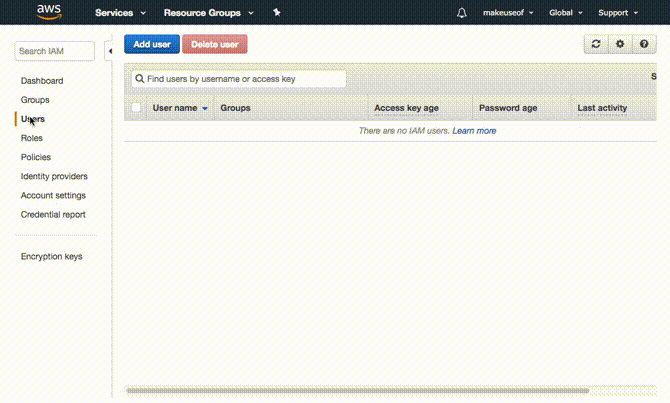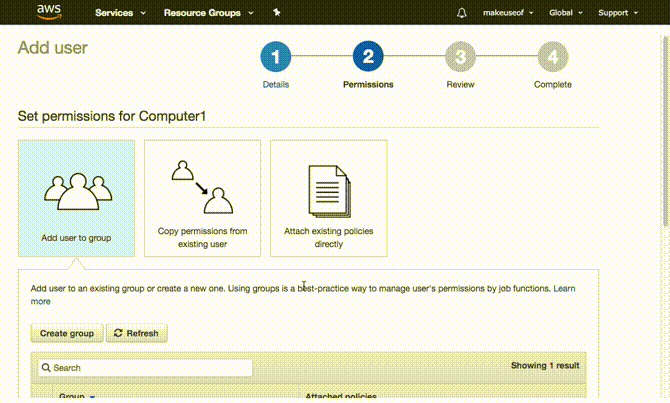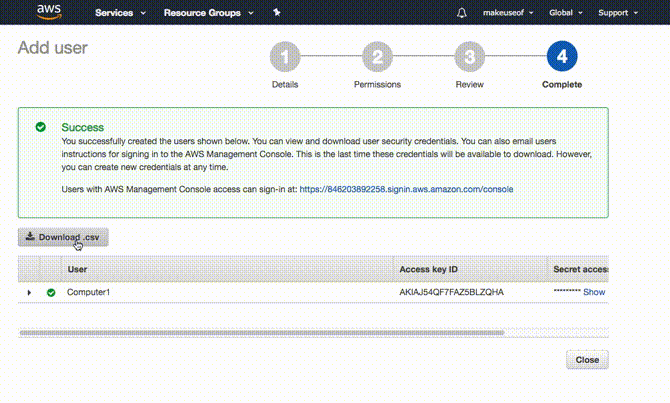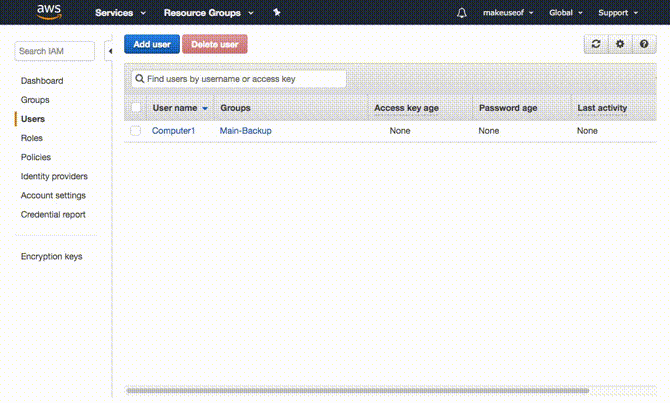
È tempo di decidere il livello di accesso che il tuo computer dovrà accedere ad AWS. Il modo più semplice e sicuro per farlo sarà creare un gruppo e a utente per il computer che si desidera eseguire il backup. Quindi concedere l'accesso o aggiungere un'autorizzazione a quel gruppo per accedere solo a S3. Ci sono numerosi vantaggi con questo approccio. Le credenziali fornite a detto gruppo sono limitate a S3 e non possono essere utilizzate per accedere ad altri servizi AWS. Inoltre, nel malaugurato caso in cui le tue credenziali perdano, devi solo eliminare l'accesso al gruppo e il tuo account AWS sarà al sicuro.
In realtà ha più senso creare prima il gruppo. Per fare questo espandere Crea singoli utenti IAM e clicca Gestisci utenti. Clicca su gruppi dal pannello a sinistra seguito da Crea nuovo gruppo. Scegli un nome per il tuo gruppo e fai clic Passo successivo. Ora allegheremo l'autorizzazione o la norma per questo gruppo. Poiché si desidera che solo questo gruppo abbia accesso a S3, filtrare l'elenco digitando S3 nel filtro. Assicurarsi che AmazonS3FullAccess è selezionato e fare clic Passo successivo infine seguito da Creare un gruppo.
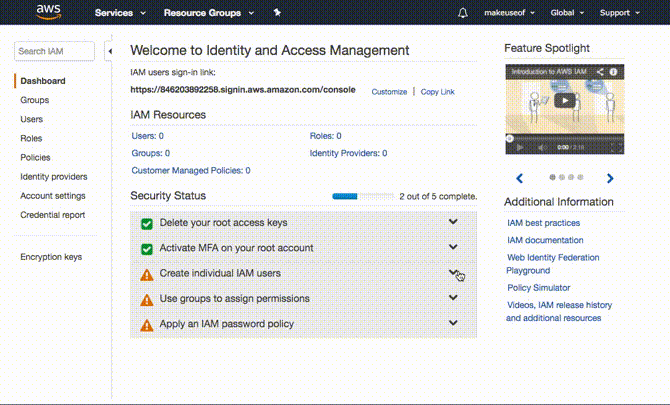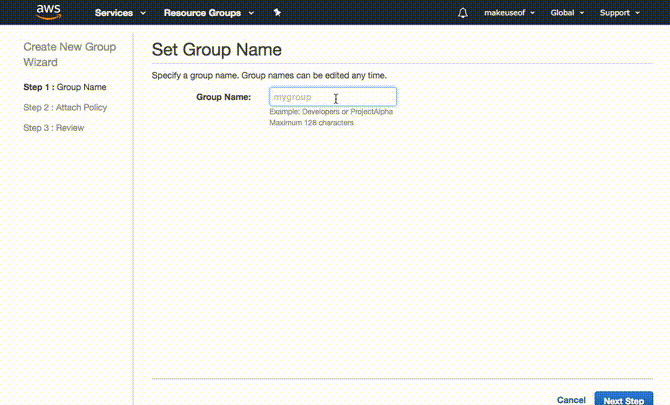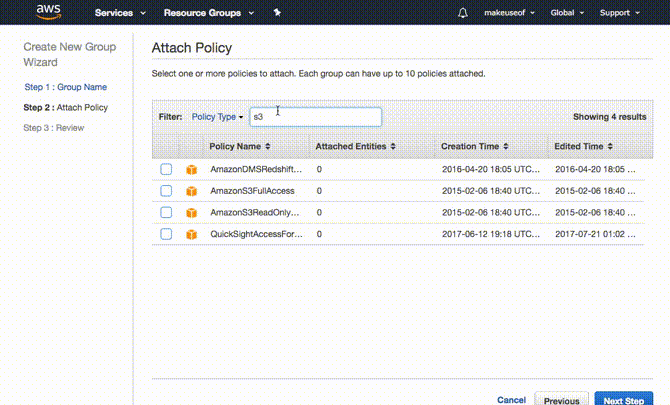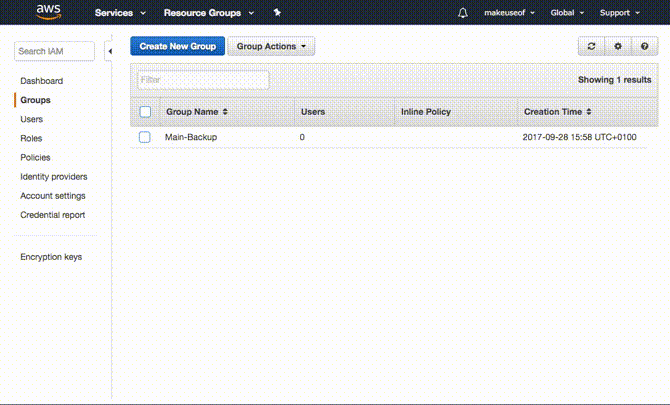
Crea un utente
Tutto quello che devi fare ora è creare un utente e aggiungerlo al gruppo che hai creato. Selezionare utenti dal pannello a sinistra e fai clic Aggiungi utente. Scegli qualsiasi nome utente che ti piace, in tipo di accesso assicurati Accesso programmatico è selezionato e fare clic Avanti: Autorizzazioni. Nella pagina successiva selezionare il gruppo creato e fare clic su Avanti: Revisione. AWS confermerà che stai aggiungendo questo utente al gruppo selezionato e confermerà le autorizzazioni concesse. Clicca su Creare un utente per passare alla pagina successiva.
Ora vedrai un ID chiave di accesso e a Chiave d'accesso segreta. Questi sono auto-generati e visualizzati solo una volta. Puoi copiarli e incollarli in un luogo sicuro oppure fare clic Scarica .csv che scaricherà un foglio di calcolo contenente questi dettagli. Questo è l'equivalente del nome utente e della password che il computer utilizzerà per accedere a S3.
Vale la pena notare che è necessario trattarli con il massimo livello di sicurezza. Se si perde la chiave di accesso segreta, non è possibile recuperarla. Dovrai tornare alla console AWS e generarne una nuova.
Il tuo primo secchio
È giunto il momento di creare un luogo per i tuoi dati. S3 ha negozi chiamati secchi. Ogni nome di bucket deve essere univoco a livello globale, ovvero quando crei un bucket sarai l'unico sul pianeta con quel nome di bucket. Ogni bucket può avere un proprio set di regole di configurazione impostato su di esso. Puoi avere versioning abilitato sui bucket in modo da conservare copie dei file che aggiorni in modo da poter ripristinare le versioni precedenti dei file. Ci sono anche opzioni per replica tra regioni in modo da poter eseguire ulteriormente il backup dei dati in un'altra regione in un altro paese.
Puoi accedere a S3 navigando verso Servizi> Memoria> S3. Creare un bucket è semplice come fare clic su Crea secchio pulsante. Dopo aver scelto un nome univoco a livello globale (solo lettere minuscole), seleziona una regione in cui desideri vivere il tuo bucket. Facendo clic su Creare pulsante ti darà finalmente il tuo primo secchio.
La linea di comando è vita
Se la riga di comando è la tua arma preferita 4 modi per insegnare a te stesso i comandi terminal in LinuxSe vuoi diventare un vero maestro di Linux, avere una conoscenza dei terminali è una buona idea. Ecco i metodi che puoi usare per iniziare a insegnare te stesso. Leggi di più , è possibile accedere al bucket S3 appena creato utilizzando s3cmd che puoi scarica da qui. Dopo aver scelto l'ultima versione, scarica l'archivio zip in una cartella di tua scelta. L'ultima versione attuale è la 2.0.0 che utilizzerai nel nostro esempio. Per decomprimere e installare s3cmd aprire una finestra del terminale e digitare:
sudo apt installa python-setuptools. decomprimere s3cmd-2.0.0. cd s3cmd-2.0.0. sudo python setup.py installs3cmd è ora installato sul tuo sistema ed è pronto per essere configurato e collegato al tuo account AWS. Assicurati di avere il tuo ID chiave di accesso e Chiave d'accesso segreta da quando hai creato il tuo utente. Inizia digitando:
s3cmd --configureTi verrà ora richiesto di inserire alcuni dettagli. Innanzitutto, verrai promosso a inserire l'ID chiave di accesso seguito dalla chiave di accesso segreta. Tutte le altre impostazioni possono essere lasciate di default premendo semplicemente il tasto Invio, tranne il tasto crittografia ambientazione. Puoi scegliere una password qui in modo che i dati inviati e estratti da S3 siano crittografati. Questo impedirà a uomo nel mezzo dell'attacco Cinque strumenti di crittografia online per proteggere la tua privacy Leggi di più o qualcuno che intercetta il tuo traffico Internet.
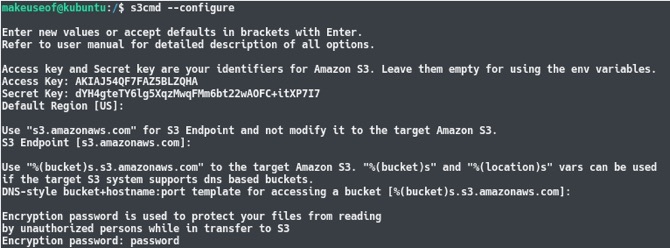
Al termine del processo di configurazione, s3cmd eseguirà un test per verificare che tutte le impostazioni funzionino e che tu possa collegarti con successo al tuo account AWS. Al termine, sarai in grado di digitare alcuni comandi come:
s3cmd lsQuesto elencherà tutti i bucket all'interno del tuo account S3. Come mostra lo screenshot qui sotto, il bucket che hai creato è visibile!

Sincronizzazione tramite riga di comando
Il comando di sincronizzazione per s3cmd è estremamente versatile. È molto simile al modo in cui normalmente si copia un file in Linux e ha un aspetto simile al seguente:
s3cmd sync [PERCORSO LOCALE] [PERCORSO REMOTO] [PARAMETRI]Prova il suo utilizzo con una semplice sincronizzazione. Innanzitutto, crea due file di testo usando il toccare comando, quindi utilizzare il sync comando per inviare i file appena creati nel bucket creato in precedenza. Aggiorna il bucket S3; noterai che i file sono stati effettivamente inviati a S3! Assicurarsi di sostituire il percorso locale con il percorso locale sul computer e di modificare il percorso remoto con il nome del bucket. Per realizzare questo tipo:
toccare file-1.txt. toccare file-2.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup
Il sync comando, come detto, controlla prima e confronta entrambe le directory. Se un file non esiste in S3, verrà caricato. Inoltre, se esiste un file, controllerà se è stato aggiornato prima di copiarlo su S3. Se si desidera eliminare anche i file eliminati localmente, è possibile eseguire il comando con il -delete-rimosso parametro. Prova questo eliminando prima uno dei file di testo che abbiamo creato seguito dal comando di sincronizzazione con il parametro aggiuntivo. Se poi aggiorni il tuo bucket S3, il file eliminato è stato rimosso da S3! Per provare questo, digitare:
rm file-1.txt. s3cmd sync ~ / Backup s3: // makeuseof-backup --delete-rimosso
A colpo d'occhio, puoi vedere quanto è interessante questo metodo. Se volessi eseguire il backup di qualcosa sul tuo account AWS, potresti farlo aggiungere il comando di sincronizzazione a un processo cron Come pianificare le attività in Linux con Cron e CrontabLa capacità di automatizzare le attività è una di quelle tecnologie futuristiche che è già qui. Ogni utente Linux può beneficiare del sistema di pianificazione e delle attività dell'utente, grazie a cron, un servizio in background di facile utilizzo. Leggi di più e backup automatico del computer su S3.
L'alternativa alla GUI
Se la riga di comando non fa per te, esiste un'alternativa all'interfaccia grafica (GUI) a s3cmd: Cloud Explorer. Sebbene non abbia un'interfaccia molto moderna, ha alcune funzionalità interessanti. Ironia della sorte, il metodo più semplice per mettere le mani sull'ultima versione è tramite la riga di comando. Dopo aver aperto una finestra del terminale con una cartella in cui desideri installarla, digita:
sudo apt -y install Come usare APT e dire addio a APT-GET in Debian e UbuntuLinux è in uno stato di evoluzione permanente; i cambiamenti importanti a volte sono facilmente persi. Mentre alcuni miglioramenti possono essere sorprendenti, altri hanno semplicemente senso: dai un'occhiata a questi cambiamenti apt-get e vedi cosa ne pensi. Leggi di più git formica openjdk-8-senza testa. clone git https://github.com/rusher81572/cloudExplorer.git. cd cloudExplorer. formica. cd dist. java -jar CloudExplorer.jarAll'avvio dell'interfaccia, alcuni dei campi richiesti dovrebbero già sembrare familiari. Per caricare il tuo account AWS, inserisci la chiave di accesso, la chiave segreta, fornisci un nome per il tuo account e fai clic Salva.
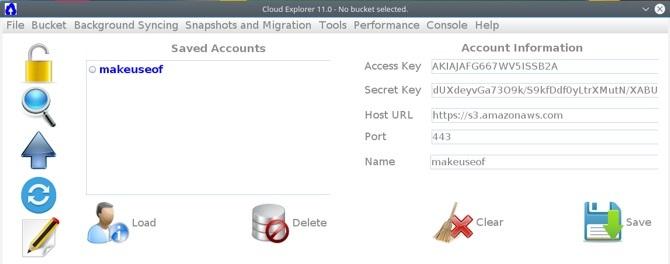
Ora puoi fare clic sul tuo profilo salvato e ottenere l'accesso al tuo bucket.
Esplorare l'esploratore
Dando una rapida occhiata all'interfaccia, vedrai quanto segue:
- Disconnettersi
- Esplora e cerca
- Caricare files
- Sync
- Editor di testo
- Un pannello per un elenco dei tuoi secchi
- Un pannello per la navigazione di un bucket selezionato
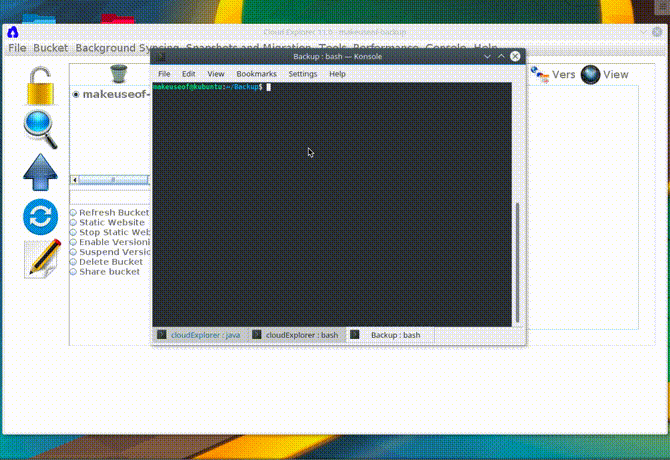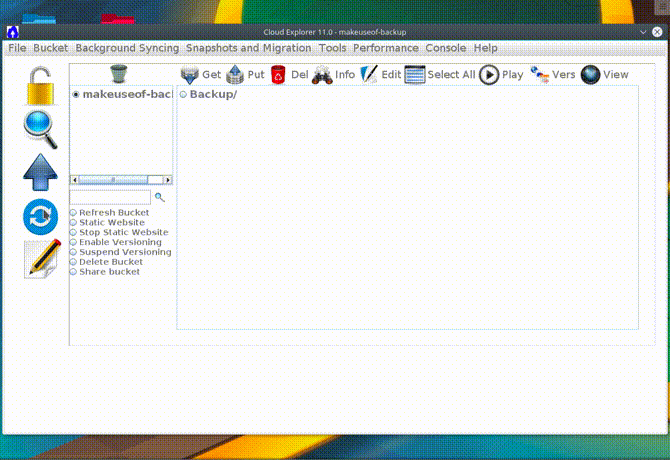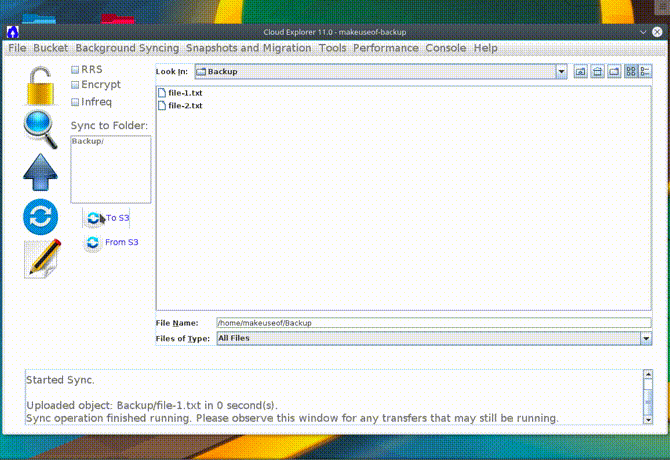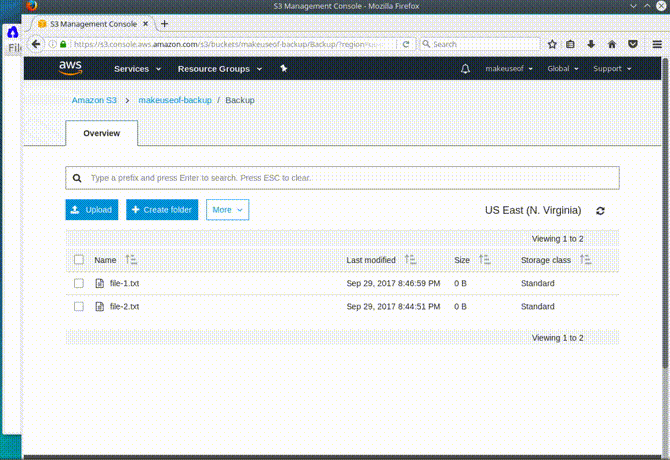
L'impostazione delle funzionalità di sincronizzazione di Cloud Explorer è simile a s3cmd. Innanzitutto, crea un file che non esiste nel bucket S3. Quindi, fare clic su Sync all'interno di Cloud Explorer e cerca la cartella che desideri sincronizzare con S3. Cliccando su A S3 controllerà le differenze tra la cartella sul tuo computer locale e la cartella con S3 e caricherà tutte le differenze che trova.
Quando aggiorni il bucket S3 nel browser, noterai che il nuovo file è stato inviato a S3. Sfortunatamente, la funzione di sincronizzazione di Cloud Explorer non soddisfa i file che hai eliminato sul tuo computer locale. Quindi, se rimuovi un file localmente, rimarrà comunque in S3. Questo è qualcosa da tenere a mente.
Gli utenti domestici possono utilizzare l'archiviazione cloud orientata al business
Mentre AWS è una soluzione progettata per consentire alle aziende di sfruttare il cloud, non vi è alcun motivo per cui gli utenti domestici non debbano partecipare all'azione. L'uso della piattaforma cloud leader nel mondo comporta numerosi vantaggi. Non devi mai preoccuparti di aggiornare l'hardware o di pagare per tutto ciò che non usi. Un altro fatto interessante è che AWS ha una quota di mercato maggiore rispetto ai prossimi 10 fornitori messi insieme. Questa è un'indicazione di quanto siano avanti. La configurazione di AWS come soluzione di backup richiede:
- Creare un account
- Proteggi il tuo account con MFA.
- Creazione di un gruppo e assegnazione delle autorizzazioni al gruppo.
- Aggiunta di un utente al gruppo.
- Crea il tuo primo secchio.
- Utilizzo della riga di comando per la sincronizzazione con S3.
- Un'alternativa della GUI per S3.
Attualmente usi AWS per qualcosa? Quale fornitore di backup cloud usi attualmente? Quali funzionalità cerchi quando scegli un fornitore di backup? Fateci sapere nei commenti qui sotto!
Yusuf vuole vivere in un mondo pieno di aziende innovative, smartphone che vengono forniti in bundle con caffè torrefatto scuro e computer con campi di forza idrofobici che respingono ulteriormente la polvere. Come analista aziendale e laureato alla Durban University of Technology, con oltre 10 anni di esperienza in un settore tecnologico in rapida crescita, gli piace essere il medio tra...