Il percorso per diventare un programmatore esperto e di successo è difficile, ma sicuramente realizzabile. Le strutture di dati sono un componente fondamentale che ogni studente di programmazione deve padroneggiare e probabilmente hai già imparato o lavorato con alcune strutture di dati di base come array o elenchi.
Gli intervistatori tendono a preferire porre domande relative alle strutture dati, quindi se ti stai preparando per un colloquio di lavoro, dovrai rispolverare le tue conoscenze sulle strutture dati. Continua a leggere mentre elenchiamo le strutture dati più importanti per programmatori e colloqui di lavoro.
Gli elenchi collegati sono una delle strutture dati più basilari e spesso il punto di partenza per gli studenti nella maggior parte dei corsi sulle strutture dati. Gli elenchi collegati sono strutture di dati lineari che consentono l'accesso sequenziale ai dati.
Gli elementi all'interno dell'elenco collegato sono archiviati in singoli nodi che sono collegati (collegati) utilizzando i puntatori. Puoi pensare a una lista collegata come a una catena di nodi collegati tra loro tramite diversi puntatori.
Imparentato: Introduzione all'utilizzo di elenchi collegati in Java
Prima di entrare nello specifico dei diversi tipi di elenchi collegati, è fondamentale comprendere la struttura e l'implementazione del singolo nodo. Ogni nodo in una lista collegata ha almeno un puntatore (i nodi della lista doppiamente collegati hanno due puntatori) che lo connette al nodo successivo nella lista e all'elemento di dati stesso.
Ogni lista collegata ha un nodo di testa e di coda. I nodi dell'elenco a collegamento singolo hanno solo un puntatore che punta al nodo successivo nella catena. Oltre al puntatore successivo, i nodi della lista doppiamente collegati hanno un altro puntatore che punta al nodo precedente nella catena.
Le domande dell'intervista relative agli elenchi collegati di solito ruotano attorno all'inserimento, alla ricerca o alla cancellazione di un elemento specifico. L'inserimento in una lista collegata richiede tempo O (1), ma l'eliminazione e la ricerca possono richiedere tempo O (n) nel caso peggiore. Quindi le liste collegate non sono l'ideale.
2. Albero binario
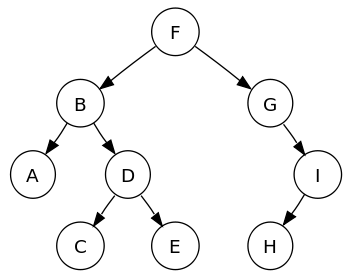
Gli alberi binari sono il sottoinsieme più popolare della struttura dei dati della famiglia di alberi; gli elementi in un albero binario sono disposti in una gerarchia. Altri tipi di alberi includono AVL, rosso-nero, alberi B, ecc. I nodi dell'albero binario contengono l'elemento dati e due puntatori a ciascun nodo figlio.
Ciascun nodo padre in un albero binario può avere un massimo di due nodi figlio e ogni nodo figlio, a sua volta, può essere padre di due nodi.
Imparentato: Una guida per principianti agli alberi binari
Un albero di ricerca binario (BST) memorizza i dati in un ordine ordinato, in cui gli elementi con un valore-chiave minore del genitore il nodo viene archiviato a sinistra e gli elementi con un valore-chiave maggiore del nodo padre vengono archiviati sul Giusto.
Gli alberi binari vengono comunemente richiesti nelle interviste, quindi se ti stai preparando per un'intervista, dovresti sapere come appiattire un albero binario, cercare un elemento specifico e altro ancora.
3. Tabella hash
Le tabelle hash o le mappe hash sono una struttura dati altamente efficiente che memorizza i dati in un formato array. A ogni elemento di dati viene assegnato un valore di indice univoco in una tabella hash, che consente una ricerca e una cancellazione efficienti.
Il processo di assegnazione o mappatura delle chiavi in una mappa hash è chiamato hashing. Più efficiente è la funzione hash, migliore è l'efficienza della tabella hash stessa.
Ogni tabella hash memorizza gli elementi dei dati in una coppia indice-valore.
Dove value sono i dati da archiviare e index è l'intero univoco utilizzato per mappare l'elemento nella tabella. Le funzioni hash possono essere molto complesse o molto semplici, a seconda dell'efficienza richiesta della tabella hash e di come si risolveranno le collisioni.
Le collisioni si verificano spesso quando una funzione hash produce la stessa mappatura per elementi diversi; le collisioni delle mappe hash possono essere risolte in diversi modi, utilizzando l'indirizzamento aperto o il concatenamento.
Le tabelle hash o le mappe hash hanno una varietà di applicazioni diverse, inclusa la crittografia. Sono la struttura dati di prima scelta quando è richiesto l'inserimento o la ricerca in tempo O(1) costante.
4. pile
Gli stack sono una delle strutture dati più semplici e sono abbastanza facili da padroneggiare. Una struttura di dati stack è essenzialmente qualsiasi stack della vita reale (si pensi a una pila di scatole o piatti) e opera in modo LIFO (Last In First Out).
La proprietà LIFO di Stacks indica che si accederà per primo all'elemento inserito per ultimo. Non puoi accedere agli elementi sotto l'elemento superiore in una pila senza far apparire gli elementi sopra di esso.
Gli stack hanno due operazioni principali: push e pop. Push viene utilizzato per inserire un elemento nello stack e pop rimuove l'elemento più in alto dallo stack.
Hanno anche molte applicazioni utili, quindi è molto comune per gli intervistatori fare domande relative agli stack. Sapere come invertire uno stack e valutare le espressioni è abbastanza essenziale.
5. code
Le code sono simili agli stack ma funzionano in modo FIFO (First In First Out), il che significa che puoi accedere agli elementi che hai inserito in precedenza. La struttura dei dati della coda può essere visualizzata come qualsiasi coda della vita reale, in cui le persone sono posizionate in base al loro ordine di arrivo.
L'operazione di inserimento di una coda è chiamata accodamento e l'eliminazione/rimozione di un elemento dall'inizio della coda è definita rimozione dalla coda.
Imparentato: Una guida per principianti per comprendere le code e le code prioritarie
Le code prioritarie sono un'applicazione integrale delle code in molte applicazioni vitali come la pianificazione della CPU. In una coda prioritaria, gli elementi vengono ordinati in base alla loro priorità anziché all'ordine di arrivo.
6. cumuli
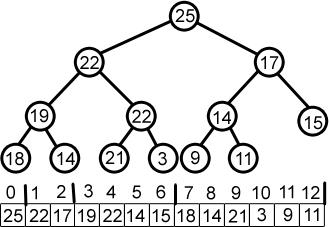
Gli heap sono un tipo di albero binario in cui i nodi sono disposti in ordine crescente o decrescente. In un Min Heap, il valore della chiave del genitore è uguale o inferiore a quello dei suoi figli e il nodo radice contiene il valore minimo dell'intero heap.
Allo stesso modo, il nodo radice di un Max Heap contiene il valore massimo della chiave dell'heap; è necessario mantenere la proprietà heap min/max in tutto l'heap.
Imparentato: Cumuli vs. Stack: cosa li distingue?
Gli heap hanno molte applicazioni grazie alla loro natura molto efficiente; principalmente, le code prioritarie sono spesso implementate tramite heap. Sono anche un componente fondamentale negli algoritmi heapsort.
Impara le strutture dei dati
Le strutture di dati possono sembrare strazianti all'inizio, ma dedica abbastanza tempo e le troverai facili come una torta.
Sono una parte vitale della programmazione e quasi tutti i progetti richiedono il loro utilizzo. Sapere quale struttura dati è ideale per un determinato scenario è fondamentale.
Questi algoritmi sono essenziali per il flusso di lavoro di ogni programmatore.
Leggi Avanti
- Programmazione
- Analisi dei dati
- Suggerimenti per la codifica

Fahad è uno scrittore presso MakeUseOf e attualmente si sta laureando in Informatica. Come appassionato scrittore di tecnologia, si assicura di rimanere aggiornato con le ultime tecnologie. Si ritrova particolarmente interessato al calcio e alla tecnologia.
Iscriviti alla nostra Newsletter
Iscriviti alla nostra newsletter per suggerimenti tecnici, recensioni, ebook gratuiti e offerte esclusive!
Clicca qui per iscriverti