Annuncio
Se tu gestire un sito web 10 modi per creare un sito Web piccolo e semplice senza eccessiWordPress può essere eccessivo. Come dimostrano questi altri servizi eccellenti, WordPress non è tutto e termina tutta la creazione di siti Web. Se vuoi soluzioni più semplici, c'è una varietà tra cui scegliere. Per saperne di più , probabilmente hai sentito parlare di un file robots.txt (o dello "standard di esclusione dei robot"). Che tu l'abbia fatto o no, è ora di impararlo, perché questo semplice file di testo è una parte cruciale del tuo sito. Potrebbe sembrare insignificante, ma potresti essere sorpreso di quanto sia importante.
Diamo un'occhiata a cos'è un file robots.txt, cosa fa e come configurarlo correttamente per il tuo sito.
Che cos'è un file robots.txt?
Per capire come funziona un file robots.txt, devi sapere un po' di motori di ricerca Come funzionano i motori di ricerca?Per molte persone, Google È Internet. È probabilmente l'invenzione più importante dopo Internet stessa. E mentre i motori di ricerca sono cambiati molto da allora, i principi alla base sono sempre gli stessi. Per saperne di più . La versione breve è che inviano "crawler", che sono programmi che perlustrano Internet alla ricerca di informazioni. Quindi memorizzano alcune di queste informazioni in modo da poter indirizzare le persone ad esse in un secondo momento.
Questi crawler, noti anche come "bot" o "spider", trovano pagine da miliardi di siti web. I motori di ricerca danno loro indicazioni su dove andare, ma i singoli siti web possono anche comunicare con i bot e dire loro quali pagine dovrebbero guardare.
La maggior parte delle volte, in realtà fanno l'opposto e dicono loro quali pagine stanno non dovrebbe guardare. Cose come pagine amministrative, portali di backend, pagine di categorie e tag e altre cose che i proprietari di siti non vogliono che vengano visualizzate sui motori di ricerca. Queste pagine sono ancora visibili agli utenti e sono accessibili a chiunque disponga dell'autorizzazione (che spesso sono tutti).
Ma dicendo a quei ragni di non indicizzare alcune pagine, il file robots.txt fa un favore a tutti. Se hai cercato "MakeUseOf" su un motore di ricerca, vorresti che le nostre pagine amministrative fossero in alto nelle classifiche? No. Non servirebbe a nessuno, quindi diciamo ai motori di ricerca di non visualizzarli. Può anche essere utilizzato per impedire ai motori di ricerca di controllare le pagine che potrebbero non aiutarli a classificare il tuo sito nei risultati di ricerca.
In breve, robots.txt dice ai web crawler cosa fare.
I crawler possono ignorare robots.txt?
I crawler ignorano mai i file robots.txt? Sì. In effetti, molti crawler fare ignoralo. In genere, tuttavia, quei crawler non provengono da motori di ricerca affidabili. Provengono da spammer, raccoglitori di email e altri tipi di bot automatizzati Come costruire un crawler Web di base per estrarre informazioni da un sito WebHai mai desiderato acquisire informazioni da un sito Web? Ecco come scrivere un crawler per navigare in un sito Web ed estrarre ciò di cui hai bisogno. Per saperne di più che vagano per Internet. È importante tenerlo a mente - l'utilizzo dello standard di esclusione dei robot per dire ai bot di tenersi alla larga non è una misura di sicurezza efficace. In effetti, alcuni bot potrebbero cominciare con le pagine a cui dici loro di non andare.
I motori di ricerca, tuttavia, faranno come dice il tuo file robots.txt purché sia formattato correttamente.
Come scrivere un file robots.txt
Ci sono alcune parti diverse che entrano in un file standard di esclusione del robot. Li analizzerò ciascuno individualmente qui.
Dichiarazione agente utente
Prima di dire a un bot quali pagine non dovrebbe guardare, devi specificare con quale bot stai parlando. La maggior parte delle volte utilizzerai una semplice dichiarazione che significa "tutti i bot". Sembra così:
Agente utente: *L'asterisco sta per "tutti i bot". Potresti, tuttavia, specificare le pagine per determinati bot. Per fare ciò, dovrai conoscere il nome del bot per il quale stai definendo le linee guida. Potrebbe assomigliare a questo:
Agente utente: Googlebot. [elenco di pagine da non eseguire la scansione] Agente utente: Googlebot-Image/1.0. [elenco delle pagine da non eseguire la scansione] Agente utente: Bingbot. [elenco di pagine da non eseguire la scansione]E così via. Se scopri un bot di cui non vuoi affatto eseguire la scansione del tuo sito, puoi specificare anche quello.
Per trovare i nomi degli agenti utente, controlla useragentstring.com [Non più disponibile].
Disabilitare le pagine
Questa è la parte principale del file di esclusione del robot. Con una semplice dichiarazione, dici a un bot oa un gruppo di bot di non eseguire la scansione di determinate pagine. La sintassi è facile. Ecco come impediresti l'accesso a tutto ciò che si trova nella directory "admin" del tuo sito:
Non consentire: /admin/Quella linea impedirebbe ai bot di eseguire la scansione di tuosito.com/admin, tuosito.com/admin/login, tuosito.com/admin/files/secret.html e qualsiasi altra cosa che rientri nella directory di amministrazione.
Per non consentire una singola pagina, è sufficiente specificarla nella riga Disallow:
Non consentire: /public/exception.htmlOra la pagina "eccezione" non verrà strascicata, ma tutto il resto nella cartella "pubblica" lo farà.
Per includere più directory o pagine, è sufficiente elencarle nelle righe successive:
Non consentire: /privato/ Non consentire: /admin/ Non consentire: /cgi-bin/ Non consentire: /temp/Queste quattro righe si applicheranno a qualsiasi agente utente specificato nella parte superiore della sezione.
Se vuoi impedire ai bot di guardare qualsiasi pagina del tuo sito, usa questo:
Non consentire: /Stabilire standard diversi per i robot
Come abbiamo visto sopra, puoi specificare determinate pagine per diversi bot. Combinando i due elementi precedenti, ecco come appare:
Agente utente: googlebot. Non consentire: /admin/ Disallow: /private/ Agente utente: bingbot. Non consentire: /admin/ Non consentire: /privato/ Non consentire: /segreto/Le sezioni "admin" e "private" saranno invisibili su Google e Bing, ma Google vedrà la directory "segreta", mentre Bing no.
È possibile specificare regole generali per tutti i bot utilizzando l'agente utente asterisco e quindi fornire istruzioni specifiche ai bot anche nelle sezioni successive.
Mettere tutto insieme
Con le conoscenze di cui sopra, puoi scrivere un file robots.txt completo. Avvia il tuo editor di testo preferito (siamo fan di Sublime 11 suggerimenti di testo sublime per la produttività e un flusso di lavoro più veloceSublime Text è un editor di testo versatile e uno standard di riferimento per molti programmatori. I nostri suggerimenti si concentrano su una codifica efficiente, ma gli utenti generici apprezzeranno le scorciatoie da tastiera. Per saperne di più qui intorno) e inizia a far sapere ai bot che non sono i benvenuti in alcune parti del tuo sito.
Se desideri vedere un esempio di un file robots.txt, vai su qualsiasi sito e aggiungi "/robots.txt" alla fine. Ecco parte del file robots.txt di Giant Bicycles:
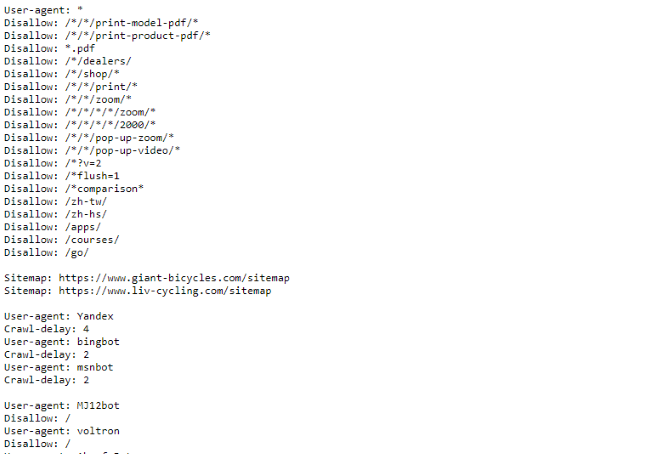
Come puoi vedere, ci sono alcune pagine che non vogliono che vengano visualizzate sui motori di ricerca. Hanno anche incluso alcune cose di cui non abbiamo ancora parlato. Diamo un'occhiata a cos'altro puoi fare nel tuo file di esclusione del robot.
Localizzare la tua Sitemap
Se il tuo file robots.txt dice ai bot dove non andare, il tuo la mappa del sito fa il contrario Come creare una mappa del sito XML in 4 semplici passaggiEsistono due tipi di sitemap: una pagina HTML o un file XML. Una sitemap HTML è una singola pagina che mostra ai visitatori tutte le pagine di un sito web e di solito ha collegamenti a quelle... Per saperne di più e li aiuta a trovare quello che stanno cercando. E mentre i motori di ricerca probabilmente sanno già dove si trova la tua sitemap, non fa male farglielo sapere di nuovo.
La dichiarazione per una posizione della mappa del sito è semplice:
Mappa del sito: [URL della mappa del sito]Questo è tutto.
Nel nostro file robots.txt, ha questo aspetto:
Mappa del sito: //www.makeuseof.com/sitemap_index.xmlQuesto è tutto quello che c'è da fare.
Impostazione di un ritardo di scansione
La direttiva sul ritardo della scansione indica a determinati motori di ricerca la frequenza con cui possono indicizzare una pagina del tuo sito. Viene misurato in secondi, anche se alcuni motori di ricerca lo interpretano in modo leggermente diverso. Alcuni vedono un ritardo di scansione di 5 come un messaggio che dice loro di attendere cinque secondi dopo ogni scansione per avviare la successiva. Altri lo interpretano come un'istruzione per eseguire la scansione di una sola pagina ogni cinque secondi.
Perché diresti a un crawler di non eseguire la scansione il più possibile? Per preservare la larghezza di banda 4 modi in cui Windows 10 sta sprecando la tua larghezza di banda InternetWindows 10 sta sprecando la tua larghezza di banda Internet? Ecco come controllare e cosa puoi fare per fermarlo. Per saperne di più . Se il tuo server fa fatica a tenere il passo con il traffico, potresti voler istituire un ritardo di scansione. In generale, la maggior parte delle persone non deve preoccuparsi di questo. I grandi siti ad alto traffico, tuttavia, potrebbero voler sperimentare un po'.
Ecco come impostare un ritardo di scansione di otto secondi:
Ritardo di scansione: 8Questo è tutto. Non tutti i motori di ricerca obbediranno alla tua direttiva. Ma non fa male chiedere. Come con la disabilitazione delle pagine, puoi impostare diversi ritardi di scansione per motori di ricerca specifici.
Caricamento del file robots.txt
Una volta impostate tutte le istruzioni nel file, puoi caricarlo sul tuo sito. Assicurati che sia un file di testo normale e che abbia il nome robots.txt. Quindi caricalo sul tuo sito in modo che possa essere trovato su tuosito.com/robots.txt.
Se usi a sistema di gestione dei contenuti I 10 sistemi di gestione dei contenuti più popolari onlineI giorni delle pagine HTML codificate a mano e della padronanza dei CSS sono ormai lontani. Installa un sistema di gestione dei contenuti (CMS) e in pochi minuti puoi avere un sito web da condividere con il mondo. Per saperne di più come WordPress, probabilmente c'è un modo specifico per farlo. Poiché è diverso in ogni sistema di gestione dei contenuti, dovrai consultare la documentazione del tuo sistema.
Alcuni sistemi potrebbero avere anche interfacce online per caricare il tuo file. Per questi, basta copiare e incollare il file creato nei passaggi precedenti.
Ricordati di aggiornare il tuo file
L'ultimo consiglio che darò è di controllare occasionalmente il file di esclusione del robot. Il tuo sito cambia e potresti dover apportare alcune modifiche. Se noti uno strano cambiamento nel traffico del tuo motore di ricerca, è una buona idea controllare anche il file. È anche possibile che la notazione standard possa cambiare in futuro. Come tutto il resto del tuo sito, vale la pena controllarlo ogni tanto.
Da quali pagine escludi i crawler dal tuo sito? Hai notato differenze nel traffico dei motori di ricerca? Condividi i tuoi consigli e commenti qui sotto!
Dann è un consulente di marketing e strategia dei contenuti che aiuta le aziende a generare domanda e lead. Scrive anche su strategia e content marketing su dannalbright.com.