Annuncio pubblicitario
Credi nell'idea che una volta pubblicato qualcosa su Internet, sia pubblicato per sempre? Bene, oggi dissiperemo quel mito.
La verità è che in molti casi è del tutto possibile sradicare le informazioni da Internet. Certo, c'è un record di pagine web che sono state eliminate se si cerca Wayback Machine, giusto? Sì, assolutamente. Sulla Wayback Machine ci sono record di pagine web che risalgono a molti anni fa: pagine che non troverai con una ricerca su Google perché la pagina web non esiste più. Qualcuno l'ha eliminato o il sito Web è stato chiuso.
Quindi, non c'è modo di aggirarlo, giusto? Le informazioni saranno incise per sempre nella pietra di Internet, lì per generazioni? Bene, non esattamente.
La verità è che mentre potrebbe essere difficile o impossibile cancellare le principali notizie che si sono moltiplicate da un sito Web o blog a un altro come un virus, in realtà è abbastanza facile sradicare completamente una pagina Web o diverse pagine Web da tutti i record di esistenza - per rimuovere quella pagina per entrambi i motori di ricerca e il
Wayback Machine La nuova macchina Wayback ti consente di tornare visivamente indietro nel tempo di InternetSembra che dal lancio di Wayback Machine nel 2001, i proprietari del sito abbiano deciso di lanciare il back-end basato su Alexa e riprogettarlo con il proprio codice open source. Dopo aver condotto i test con ... Leggi di più . C'è un problema ovviamente, ma ci arriveremo.3 modi per rimuovere le pagine del blog dalla rete
Il primo metodo è quello utilizzato dalla maggior parte dei proprietari di siti Web, perché non conoscono meglio, semplicemente eliminando le pagine Web. Ciò potrebbe accadere perché ti sei reso conto di avere contenuti duplicati sul tuo sito o perché hai una pagina che non vuoi mostrare nei risultati di ricerca.
Elimina semplicemente la pagina
Il problema dell'eliminazione completa delle pagine dal tuo sito Web è che, poiché hai già creato la pagina su al netto, è probabile che vi siano collegamenti dal proprio sito e collegamenti esterni da altri siti a quel particolare pagina. Quando lo elimini, Google riconosce immediatamente quella tua pagina come pagina mancante.
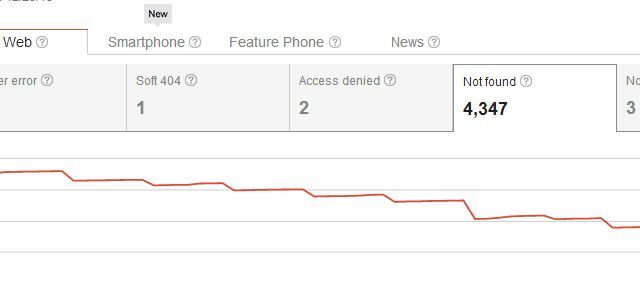
Pertanto, eliminando la tua pagina non solo hai creato un problema con gli errori di scansione "Non trovato" per te, ma hai anche creato un problema per chiunque sia mai stato collegato alla pagina. Di solito, gli utenti che accedono al tuo sito da uno di quei link esterni vedranno la tua pagina 404, che non è una grave problema, se usi qualcosa come il codice 404 personalizzato di Google per fornire agli utenti suggerimenti utili o alternative. Ma penseresti che ci potrebbero essere modi più aggraziati di eliminare pagine dai risultati di ricerca senza dare il via a tutti quei 404 "per i collegamenti in entrata esistenti, giusto?
Bene, ci sono.
Rimuovi una pagina dai risultati di ricerca di Google
Prima di tutto, dovresti capire che se la pagina web che desideri rimuovere dai risultati di ricerca di Google non è una pagina dal tuo sito, allora sei sfortunato a meno che non ci siano motivi legali o se il sito ha pubblicato le tue informazioni personali online senza di te autorizzazione. In tal caso, utilizzare Google strumento di risoluzione dei problemi di rimozione per inviare una richiesta di rimozione della pagina dai risultati di ricerca. Se hai un caso valido, potresti riscontrare un certo successo rimuovendo la pagina - ovviamente potresti avere un successo ancora maggiore contattare il proprietario del sito Web Come rimuovere false informazioni personali su InternetLa privacy online non è più garantita. Scopri come segnalare un sito Web e rimuovere le informazioni personali da Internet. Leggi di più come ho descritto come fare nel 2009.
Ora, se la pagina che desideri rimuovere dai risultati di ricerca si trova sul tuo sito, sei fortunato. Tutto quello che devi fare è creare un robots.txt e assicurati di non aver consentito né la pagina specifica che non desideri nei risultati di ricerca, né l'intera directory con i contenuti che non desideri indicizzare. Ecco come si presenta il blocco di una singola pagina.
Agente utente: * Non consentire: /my-deleted-article-that-i-want-removed.html
Puoi bloccare i bot dalla scansione di intere directory del tuo sito come segue.
Agente utente: * Non consentire: / content-about-personal-stuff /
Google ha un eccellente pagina di supporto che può aiutarti a creare un file robots.txt se non ne hai mai creato uno prima. Funziona molto bene, come ho spiegato di recente in un articolo su strutturare le offerte di sindacazione Come negoziare offerte di sindacati e proteggere le classifiche di ricercaIl sindacato è di gran moda in questi giorni. Ma improvvisamente potresti scoprire che il partner di syndication è elencato più in alto di te nei risultati di ricerca per una storia che hai scritto in origine! Proteggi le tue classifiche di ricerca. Leggi di più in modo che non ti facciano del male (chiedendo ai partner di syndication di non consentire l'indicizzazione delle loro pagine in cui sei sindacato). Una volta che il mio partner di syndication ha accettato di farlo, le pagine che erano contenuti duplicati dal mio blog sono completamente scomparse dagli elenchi di ricerca.

Solo il sito Web principale si trova al terzo posto per la pagina in cui elencano il nostro titolo, ma il mio blog è ora elencato sia al primo che al secondo posto; qualcosa che sarebbe stato quasi impossibile se un sito Web di autorità superiore avesse lasciato la pagina duplicata indicizzata.
Ciò che molte persone non capiscono è che questo è possibile anche con Internet Archive (la Wayback Machine). Ecco le linee che devi aggiungere al tuo file robots.txt per farlo accadere.
Agente utente: ia_archiver. Non consentire: / sample-category /
In questo esempio, sto dicendo a Internet Archive di rimuovere qualsiasi cosa nella sottodirectory della categoria campione sul mio sito dalla Wayback Machine. L'archivio Internet spiega come farlo nella loro pagina di aiuto sull'esclusione. Questo è anche il punto in cui spiegano che "Internet Archive non è interessato ad offrire accesso a siti Web o altri documenti Internet i cui autori non desiderano i loro materiali nella raccolta".
Ciò vola in contrasto con la credenza comune che qualsiasi cosa pubblicata su Internet venga spazzata via nell'archivio per l'eternità. No: i webmaster che possiedono il contenuto possono specificamente rimuovere il contenuto dall'archivio utilizzando l'approccio robots.txt.
Rimuovi una singola pagina con i meta tag
Se hai solo poche pagine singole che desideri rimuovere dai risultati di ricerca di Google, in realtà non devi utilizzare l'approccio robots.txt affatto, potresti semplicemente aggiungere il meta tag "robot" corretto alle singole pagine e dire ai robot di non indicizzare o seguire i collegamenti sull'intero pagina.

È possibile utilizzare la meta "robot" sopra per impedire ai robot di indicizzare la pagina, oppure si può dire specificamente al robot di Google non indicizzare, quindi la pagina viene rimossa solo dai risultati di ricerca di Google e altri robot di ricerca potrebbero comunque accedere alla pagina soddisfare.
Dipende da te come ti piacerebbe gestire cosa fanno i robot con la pagina e se la pagina viene elencata o meno. Per poche pagine singole, questo potrebbe essere l'approccio migliore. Per rimuovere un'intera directory di contenuti, vai con il metodo robots.txt.
L'idea di "Rimozione" di contenuti
Questo tipo di concetto trasforma l'intera idea di "eliminazione di contenuti da Internet". Tecnicamente, se rimuovi tutti i tuoi collegamenti a una pagina del tuo sito e la rimuovi da Ricerca Google e Internet Archive utilizzando la tecnica robots.txt, la pagina è a tutti gli effetti "cancellata" da Internet. La cosa interessante è che se ci sono collegamenti esistenti alla pagina, quei collegamenti continueranno a funzionare e non causerai 404 errori per quei visitatori.
È un approccio più "delicato" alla rimozione di contenuti da Internet senza incasinare completamente la popolarità esistente dei collegamenti del tuo sito su Internet. Alla fine, il modo in cui gestisci quali contenuti vengono raccolti dai motori di ricerca e Internet Archive dipende da te, ma sempre ricorda che, nonostante ciò che la gente dice sulla durata delle cose che vengono pubblicate online, è davvero completamente dentro di te controllo.
Ryan ha una laurea in ingegneria elettrica. Ha lavorato 13 anni in ingegneria dell'automazione, 5 anni in IT e ora è un ingegnere di app. Ex amministratore delegato di MakeUseOf, ha parlato a conferenze nazionali sulla visualizzazione dei dati ed è stato presentato su TV e radio nazionali.


